.webp)
介绍
LM Studio 是一款免费、跨平台的桌面应用,主打在本地电脑上一键下载、运行和管理开源大语言模型(LLM),无需联网、无需写代码,兼顾普通用户和开发者。
一、核心定位
本地 AI 运行平台:在你的 Windows/macOS/Linux 电脑上,离线运行 Llama、Qwen、DeepSeek、Mistral、Gemma 等主流开源 LLM。
一站式工具 = 模型下载器 + 本地聊天助手 + 模型管理器 + 本地 API 服务。
二、主要功能
模型下载与管理
内置 Hugging Face 模型搜索,一键下载 GGUF 格式模型。
本地模型库管理,支持删除、重命名、查看详情。
硬件兼容性检测,提示模型能否在你的电脑上运行。
本地聊天交互
类 ChatGPT 聊天界面,支持多轮对话、历史记录。
支持自定义系统提示词、温度、最大长度等参数。
完全离线,数据只存在本地,隐私安全。
本地 API 服务(开发者友好)
一键启动兼容 OpenAI 格式的本地 API 端点。
可被其他应用、脚本、前端 / 后端项目调用,替代云端 API。
支持 REST API,方便集成到自己的项目。
性能与兼容性
基于 llama.cpp 引擎,支持 CPU、NVIDIA CUDA、AMD、Apple Metal 加速。
Apple Silicon 额外支持 MLX 框架,速度更快。
轻量友好:8GB 内存即可运行小模型,支持 int4 量化版本。
三、适合人群
普通用户:想拥有自己的离线 AI 助手,保护隐私、不花 API 钱。
开发者:本地调试、测试、集成 LLM,快速搭建原型。
研究 / 爱好者:快速体验各种开源模型,对比效果。
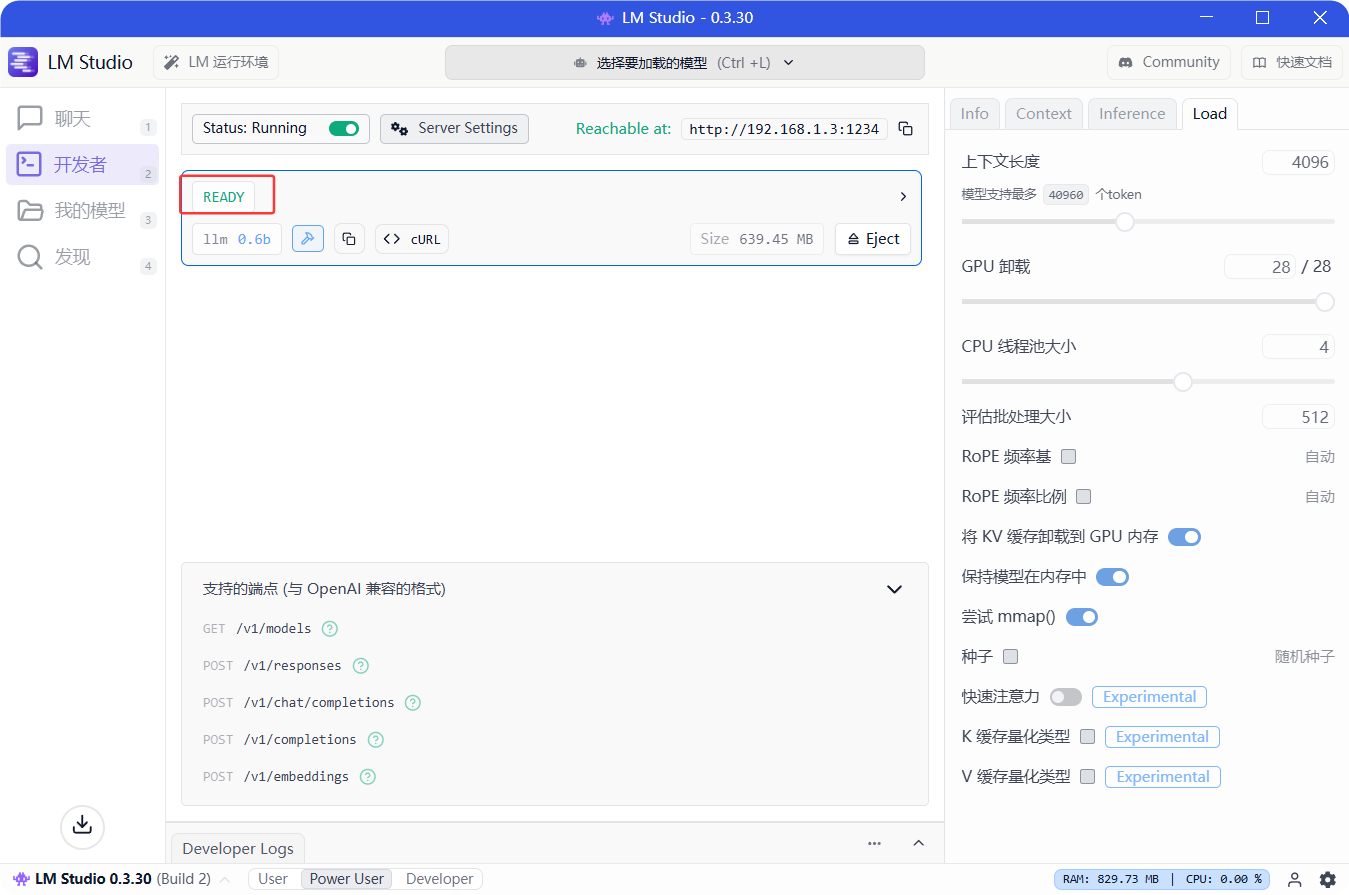
1.安装LM studio
点击下载:LM studio(Windows)
点击开发者→LM运行环境→下载所需环境内容
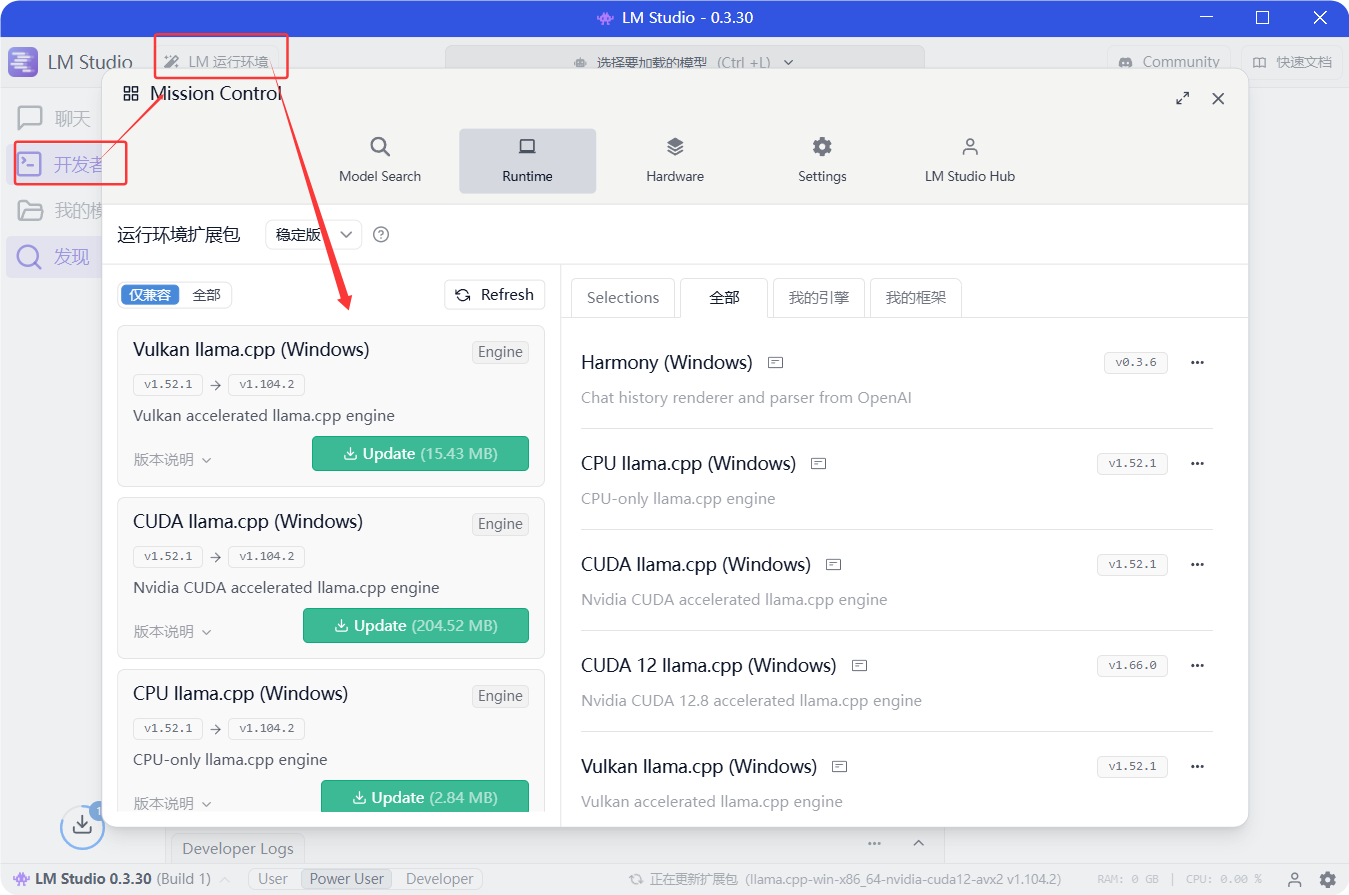
2.下载LLM模型GGUF文件
下载网站:
Qwen
Qwen3-0.6B 具有以下特点:
类型:因果语言模型
训练阶段:预训练 & 后训练
参数数量:0.6B
非嵌入参数数量:0.44B
层数:28
注意力头数(GQA):Q 为 16,KV 为 8
上下文长度:32,768
量化:q8_0
Qwen3-1.7B 具有以下特点:
类型:因果语言模型
训练阶段:预训练和后训练
参数数量:1.7B
非嵌入参数数量:1.4B
层数:28
注意力头数(GQA):Q 为 16,KV 为 8
上下文长度:32,768
量化:q8_0
Qwen3-4B 具有以下特点:
类型:因果语言模型
训练阶段:预训练和后训练
参数数量:40 亿
非嵌入参数数量:36 亿
层数:36 层
注意力头数(GQA):Q 为 32,KV 为 8
上下文长度:原生 32,768 和 使用 YaRN 的 131,072 个令牌。
量化:q8_0
Qwen3-8B 具有以下特点:
类型:因果语言模型
训练阶段:预训练和后训练
参数数量:82 亿
非嵌入参数数量:69.5 亿
层数:36 层
注意力头数(GQA):Q 为 32 个,KV 为 8 个
上下文长度:原生支持 32,768 个令牌,使用 YaRN 支持 131,072 个令牌。
量化:q8_0
Qwen3-14B 具有以下特点:
类型:因果语言模型
训练阶段:预训练 & 后训练
参数数量:148 亿
非嵌入参数数量:132 亿
层数:40
注意力头数(GQA):Q 为 40,KV 为 8
上下文长度:原生 32,768 个令牌,使用 YaRN 可达 131,072 个令牌。
量化:q8_0
DeepSeek
DeepSeek-R1-Distill 模型是基于开源模型,并使用由DeepSeek-R1生成的样本进行微调的。对其配置和分词器做了一些调整。
我们建议在使用 DeepSeek-R1 系列模型时(包括基准测试),遵循以下配置以达到预期性能:
将温度设置在0.5-0.7之间(推荐0.6),以防止无休止的重复或不连贯的输出。
避免添加系统提示;所有指令都应包含在用户提示中。
对于数学问题,建议在您的提示中加入如下指示:“请逐步推理,并将最终答案放在\boxed{}内。”
在评估模型性能时,建议进行多次测试并取平均结果。
DeepSeek-R1-1.5b-GGUF
基础模型:Qwen2.5-Math-1.5B
DeepSeek-R1-7b-GGUF
基础模型:Qwen2.5-Math-7B
DeepSeek-R1-8b-GGUF
基础模型:Llama-3.1-8B
DeepSeek-R1-14b-GGUF
基础模型:Qwen2.5-14B
注:这里的每个不同的guff需要在独立且英文文件夹里
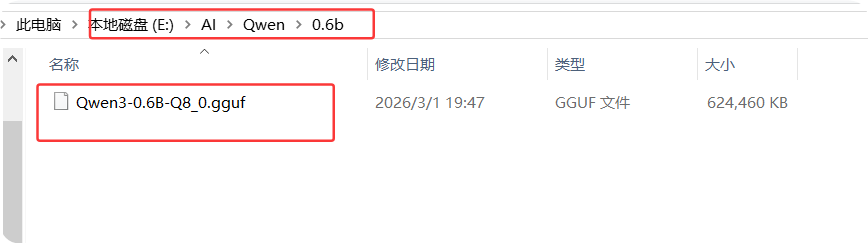
3.加载模型
3.1.选着并添加需要加载的模型
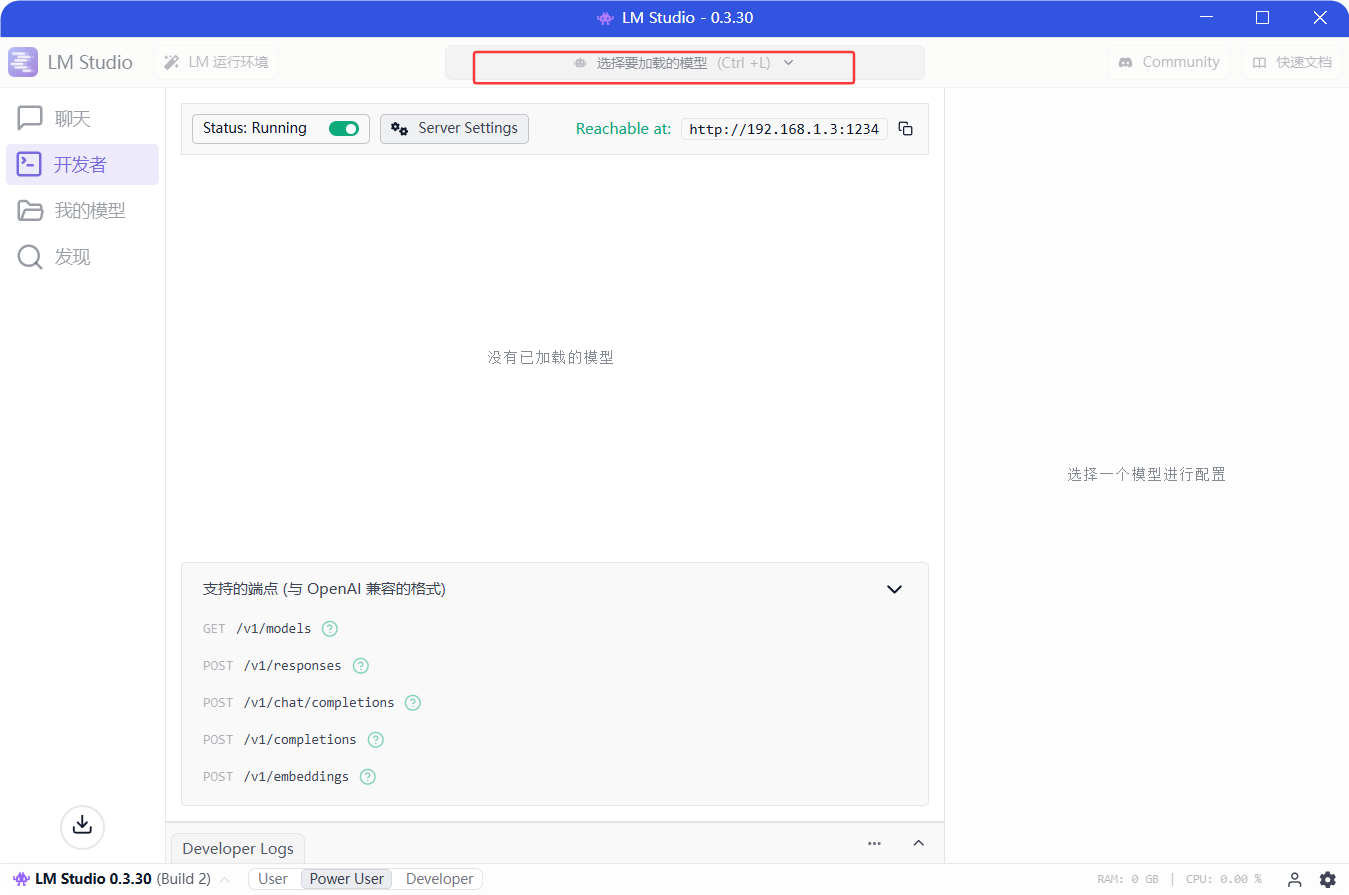
3.2.加载完成后即可进行对话